
动漫人物头像识别
1. 概述
- 当前目标
输入一张动漫图片,可以自动检测图中的人物头像位置,然后进行人物识别 - 终极目标
当有新的人物加入时,可以用最小的代价将其加入可识别的人物列表中(动态增加新人物)
可惜暂时还没想好怎么做到终极目标
- 总体框架
首先使用 Yolo 网络检测头像
再使用轻量级的图像识别网络对人物进行识别
其中 Yolo 网络使用 Yolov5,只负责检测头像,也就是在训练的时候直接将所有人物的头像当作一个类别来训练
轻量级图像识别网络使用 Resnet18 ,其以 Yolo 网络检测到的头像图片作为输入,输出识别到的人物编号
在线地址:动漫人物头像识别
2. 训练过程
2.1 数据获取
用爬虫从某个网站上借一些动漫图片(借.jpg)
分为爬取图片 URL 和爬取图片本身两部分
爬取图片 URL
1 | import time |
爬取图片本体
1 | import time |
2.2 数据标注
- 首先手动删除一下不太好的图片和重复的图片
然后使用 LabelMe 对其进行标注

使用LabelmeToYolo小工具把标签的格式从 json 转换出 Yolo 格式
- 在训练好 Yolo 模型之后,使用 Yolo 模型把原图片头像部分截取出来(这一部分代码丢失了…)
手动把截出来的头像分类
2.3 Yolo 网络训练
参考Yolov5官方教程
2.4 ResNet18 网络训练
参考 Pytorch 网络微调教程,部分细节如下
添加数据增强
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 加载数据
# 数据转换部分
data_transforms = {
'train': transforms.Compose([
# 对训练数据进行数据增强
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}训练过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
history = {
'train': {
'acc': [],
'loss': []
},
'val': {
'acc': [],
'loss': []
}
}
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 分为训练和验证两个阶段
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
history[phase]['acc'].append(epoch_acc)
history[phase]['loss'].append(epoch_loss)
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# 加载最佳参数
model.load_state_dict(best_model_wts)
return model,history加载模型与训练
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# 使用预训练了的resnet18作为识别网络
model_ft = models.resnet18(pretrained=True)
# 不冻结前面的参数
# 之所以这么做,是因为也对冻结浅层参数的做法进行了测试,但是效果不如不冻结
# 可能是因为ResNet18原本不是在动漫图上训练的原因吧
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, len(class_names))
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# 使用随机梯度下降算法
optimizer_ft = optim.SGD(model_ft.parameters(), lr=CONFIG_MODEL['learning_rate'], momentum=0.9)
# 学习率每7个epoch减少10%
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
model_ft,history = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=25)训练过程可视化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45train_history = {
'train': {
'acc': list(map(Tensor.cpu, history['train']['acc'])),
'loss': history['train']['loss']
},
'val': {
'acc': list(map(Tensor.cpu, history['val']['acc'])),
'loss': history['val']['loss']
}
}
# 画图
l1 = plt.plot(train_history['train']['acc'], linestyle=':',marker='o', label='train acc')
l2 = plt.plot(train_history['val']['acc'], linestyle='--',marker='s', label='val acc')
plt.xlabel('epoch')
plt.ylabel('acc')
plt.ylim(0,1)
plt.title(u'准确率的变化')
plt.legend(loc='lower right')
# 保存图像与参数
save_path = CONFIG_PATH['train_log_dir'] / CONFIG_MODEL['log_dir']
if not save_path.exists():
save_path.mkdir(parents=True)
plt.savefig(save_path / "train_val_acc")
np.save(save_path / "train_acc",train_history['train']['acc'])
np.save(save_path / "val_acc",train_history['val']['acc'])
plt.show()
# 画图
l1 = plt.plot(train_history['train']['loss'], linestyle=':',marker='o', label='train loss')
l2 = plt.plot(train_history['val']['loss'], linestyle='--',marker='s', label='val loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title(u'Loss的变化')
plt.legend(loc='upper right')
# 保存图像与参数
save_path = CONFIG_PATH['train_log_dir'] / CONFIG_MODEL['log_dir']
if not save_path.exists():
save_path.mkdir(parents=True)
plt.savefig(save_path / "train_val_loss")
np.save(save_path / "train_loss",train_history['train']['loss'])
np.save(save_path / "val_loss",train_history['val']['loss'])
plt.show()保存模型
1
2
3
4
5# 对比几个 batch size 大小时的训练情况
# batch size 小的时候泛化准确率反而很高
# 最终选用 4 作为 batch size 来进行训练并保存模型
model_path = CONFIG_PATH['model_save_dir'] / "resnet18.pkl"
torch.save(model_ft.to('cpu'),model_path)3.网站搭建
使用 flask 搭建后台,Vue 搭建前台(当时还不太会 Vue,写的是一塌糊涂)
项目地址:头像识别网站搭建
头像识别路由代码:
1 |
|
模型调用部分代码:
1 | # 加载 yolov5 模型,选用最小的模型 |
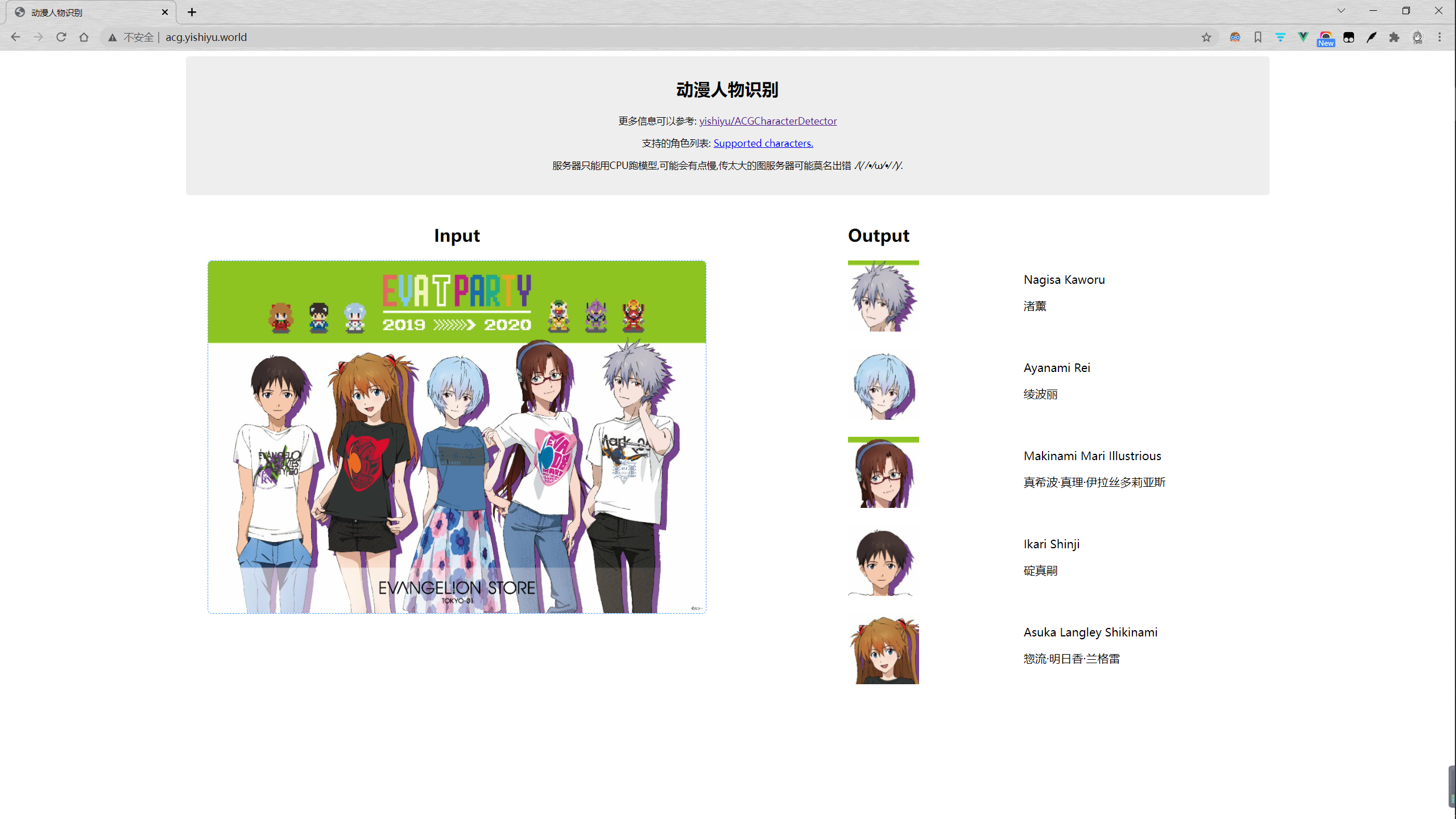
4. 结果展示
4.1 训练过程
设置学习率为 0.0001,batch size 为 4,8,16,32 进行测试

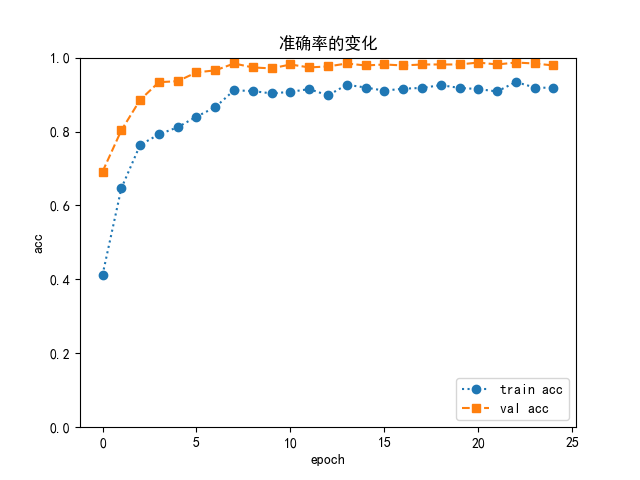
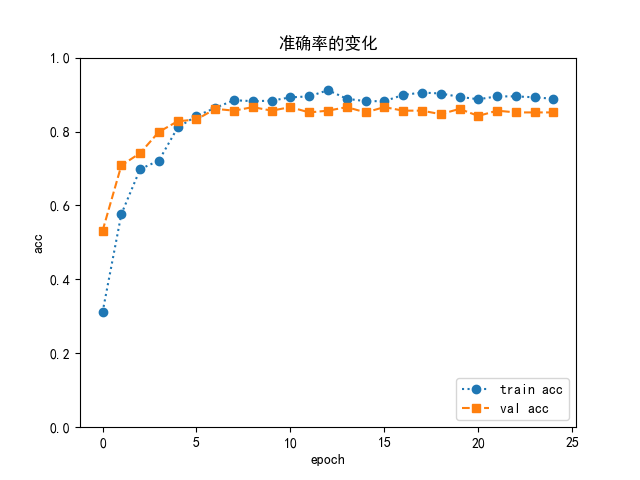

最终采用 batch size==8 情况下训练的模型
4.2 网站搭建结果
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 遗世の私语!




