
简易mips汇编器
- 简介
- 源代码
- 示例
1. 简介
本质是使用 ply 库实现的词法分析器,再将词法分析得到的 token 直接转换为对应的二进制码
结果用十六进制 ascii 码表示,可以使用 verilog 的相关函数用来初始化内存
写的目的是计算机组成实验要用…(要写一个支持 mips 指令的 CPU,为了得到 mips 指令才写的这个)
支持的指令:
| 指令类型 | 指令 | 指令格式类型 |
|---|---|---|
| 存储器访问指令 | LW Rt,Imme16(Rs) | I 型 |
| 存储器访问指令 | SW Rt,Imme16(Rs) | I 型 |
| 算术逻辑运算指令 | ADD Rd,Rs,Rt | R 型 |
| 算术逻辑运算指令 | SUB Rd,Rs,Rt | R 型 |
| 算术逻辑运算指令 | OR Rd,Rs,Rt | R 型 |
| 算术逻辑运算指令 | AND Rd,Rs,Rt | R 型 |
| 算术逻辑运算指令 | SLT Rd,Rs,Rt | R 型 |
| 程序转移指令 | BEQ Rs,Rt,Addr16 | I 型 |
| 程序转移指令 | J Addr16 | J 型 |
存在一个无关紧要的移进归约冲突,解决方法是优先移进。(其实优先移进和优先归约结果是相同的)
如果出现这个警告不用太在意。
效果图:
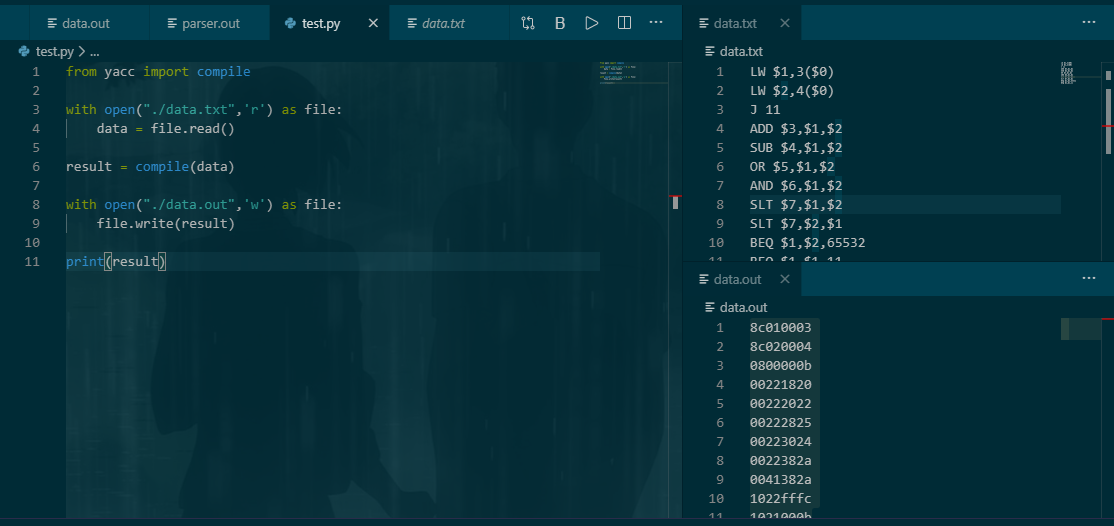
闲来无事加了个注释功能,关键字与 python 一致,转换后注释内容原封不动放进输出文件
目的是使得可以同时编写多段不同用处的代码,并用注释标明,这样就不用写一段删一段了
(存在两个问题,最后一行必须是指令或者空行,指令和注释不能同行)
效果图:
2. 源代码
- 词法分析器
- 语法分析器
- 测试文件
2.1 词法分析器
lexer.py
1 | # -- coding: utf-8 --** |
2.2 语法分析器
yacc.py
1 | # coding:utf-8 |
2.3 测试入口
test.py
1 | from yacc import compile |
3. 示例
各种不同的指令
data.txt
1 | LW $1,3($0) |
data.out
1 | 8c010003 |
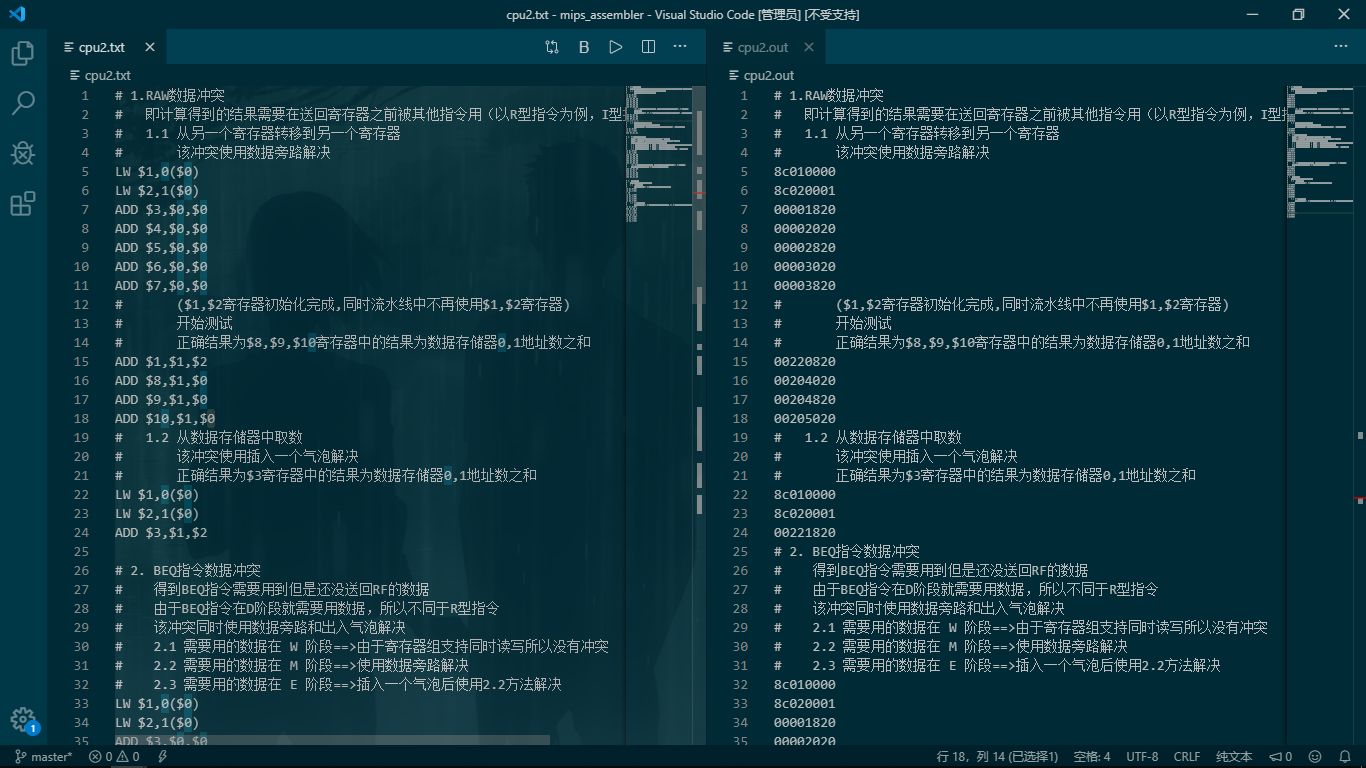
附赠一段用来测试流水线的代码
1 | # 1.RAW数据冲突 |
1 | # 1.RAW数据冲突 |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 遗世の私语!




